
在网站中使用robots.txt文件是一种控制搜索引擎爬虫访问网站内容的方法。以下是关于如何在网站中使用robots.txt的详细步骤和注意事项:
一、创建robots.txt文件
-
选择文本编辑器:启动一个文本编辑器,如Notepad++、Sublime Text或系统自带的记事本,准备编写robots.txt文件。
-
编写规则:根据网站的具体需求,精确编写控制搜索引擎爬虫访问的规则。这些规则通常涉及指定爬虫类型(User-agent)、允许或禁止访问的URL路径(Allow/Disallow)。
-
保存文件:确保文件以“robots.txt”命名,并保存为纯文本格式(.txt),文件名全部小写。同时,设置文件编码为UTF-8,以防止在不同平台出现乱码问题。
二、放置robots.txt文件
-
上传至根目录:利用FTP客户端或网站后台的文件管理系统,将编写好的robots.txt文件上传至网站的根目录下。这样,当搜索引擎访问网站时,能够通过URL(如http://www.example.com/robots.txt)直接找到该文件。
-
自定义与恢复:部分CMS系统允许在后台直接编辑robots.txt文件。若需自定义,可在相应模块(如SEO管理)中进行修改。若之后想恢复默认设置,可点击初始化按钮,系统将自动替换为系统默认的robots.txt内容。
三、编写规则详解
-
User-agent:用于指定规则适用的搜索引擎爬虫。例如,
User-agent: *表示规则适用于所有爬虫;User-agent: Googlebot则表示规则仅针对Google的爬虫。 -
Disallow:列出不希望被搜索引擎爬虫访问的URL路径。例如,
Disallow: /admin/将禁止所有爬虫访问网站的/admin/目录及其子目录和文件。 -
Allow(可选):与Disallow相反,用于明确指定允许访问的URL路径。但请注意,并非所有搜索引擎都支持Allow指令,且在使用时需谨慎以避免与Disallow指令产生冲突。
四、示例
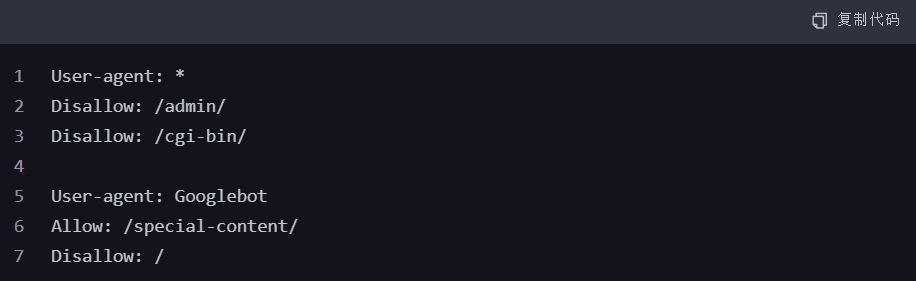
请注意,上述示例中的Disallow: /在Allow: /special-content/之后,理论上会覆盖前面的允许指令,除非搜索引擎特别支持并正确处理这种情况。实际使用中,应避免此类潜在的冲突。
此外,还可以通过Sitemap:指令提供网站地图的URL,帮助搜索引擎更全面地了解网站结构。
五、注意事项
-
确保文件名和位置正确:robots.txt文件必须准确放置于网站根目录下,且文件名需全部小写。
-
规则编写需谨慎:错误的规则设置可能导致重要页面被搜索引擎忽略,影响网站的SEO表现。因此,在编写规则时需仔细核对,确保无误。
-
定期检查和更新:随着网站内容的更新和策略的调整,建议定期检查和更新robots.txt文件,以确保其始终符合网站的实际需求。
-
了解搜索引擎的支持情况:不同搜索引擎对robots.txt文件的支持程度和解析方式可能存在差异。因此,在编写规则时,需考虑到这一点,并尽量遵循通用的最佳实践。
-
使用工具检测:利用在线工具检测robots.txt文件的语法和逻辑是否正确,以确保搜索引擎能够准确理解和执行这些规则。







